- Published on
The Profound Implications of Alpaca on OpenAI and Competition
- Authors

- Name
- John Hwang
- @nextworddev
Stanford University's release of the Alpaca model - which basically showed that an inferior foundational LLM can mimic a superior model cheaply - has massive business and science implications. Though "self-instruct" - i.e. the pattern of fine-tuning models with auto-generated demonstrations/training data - is nothing new, Stanford showed that it could be done at the scale of LLMs, and that it only costs $600!
If Stanford's results are valid (and that's a big "if"), here are the major implications:
- OpenAI's competitive moat on LLMs in terms of "science" may be smaller than we thought. Stanford or any competitor could easily spend millions - let alone $600 - to "catch up" to the state of the art. So at most, the market leader might have 3 months of a head start, unless they achieve some real algorithmic breakthrough.
- The self-instruct paradigm could work for all modalities (3D, multi-modal) to erode a competitive edge. This means AI advancement could go into overdrive from here.
- Perhaps all this explains why OpenAI lowered prices and focused on getting developer-friendly, so they can get adoption. OpenAI is self-aware of the limits of their competitive edge.
- The science implication is that it's more fruitful to focus on meta-programming LLMs than to focus on LLMs to improve their few-shot performance. How you use LLMs is more of a secret sauce than "which" LLM you use - but even this is not much of a competitive edge.
- It's difficult for the market leader to prevent laggards from copying the secret sauce to get within 5% of performance.
- The only competitive edge might just be... money. Money to spend on building awareness and forging partnerships.
Self-Instruct Process Used to Fine-tune Alpaca
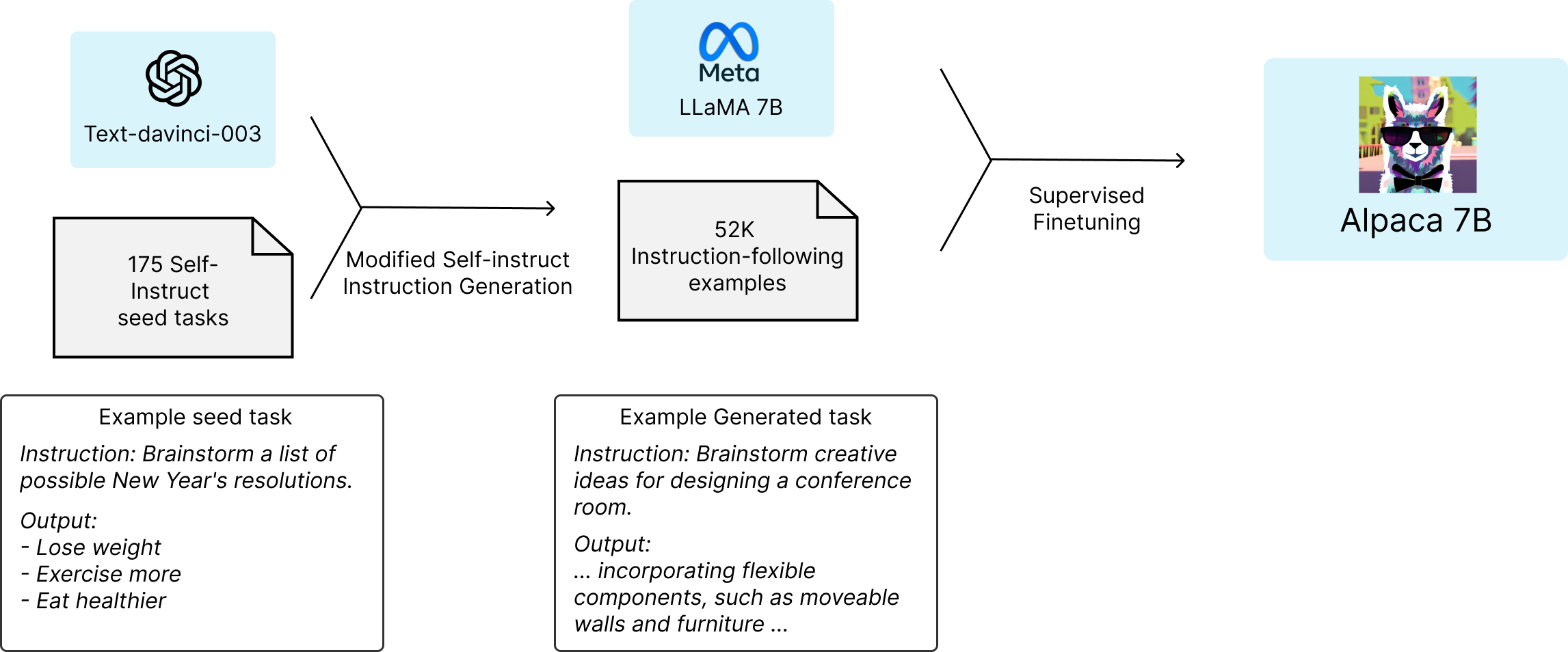
First, the Disclaimer About Alpaca
First, let's note that Alpaca's results can't be taken at face value completely because:
- It has not been subject to the same adversarial test/scrutiny that Bing Chat and ChatGPT were
- It was evaluated by the research team itself, and not by hordes of human testers, etc.
So by definition, it's ridiculous to claim that Alpaca "caught up" to InstructGPT - because it wasn't subject to the full long tail of queries.
That said, the results are still impressive because the experiment only cost $600 and a few days to achieve significant performance, nonetheless. Stanford could have easily spent $60,000 and a week if they were serious about it. So, what are the implications if Stanford or any competitor were to get serious?
Business Implications
Competitive edge of OpenAI: The obvious one is that the market leader's competitive edge is thinner than we previously thought. Even though self-instruct is not a new technique, no one predicted that it is very cheap to fine-tune a sufficiently good LLM to mimic a 10% better LLM, at least on broad queries. In retrospect, perhaps this is not surprising, given how sample efficient LLMs are (Alpaca only needed 52K samples).
Perhaps OpenAI was self-aware of these limits already, and thus adopted the "adoption at all costs" strategy instead, and cutting GPT3.5-turbo's price by 90%. If there's no material qualitative difference among LLMs, then you have to compete on privacy, latency, cost, and switching costs. Given how there are little switching costs (it's just an API call), it makes sense why OpenAI made data share opt-in, fixed performance issues, and lowered prices.
Changing Nature of Human in the Loop Work/Human Labelers: If generative AI models get really good at creating labels and serving as a reward model (through self-inspection, pruning, etc.), then human labelers will merely shift to different modalities of models. Maybe they start using screen recordings of how white-collar workers send emails, use SaaS, etc. - to automate mouse clicks and whole tasks completely - like RPA on steroids. In other words, human labelers' work will also get more complex. And even for the higher-order modalities, perhaps AI models themselves can be used to generate labels. We will all become human labelers.
Increasing legislation and regulation barriers: Maybe OpenAI freaks out and puts some terms and conditions around the use of GPT models to generate training samples for other foundational LLMs. Not sure how they can pull that off, but it's possible that legal barriers of entry into LLM development go higher (unless other large corps like Meta get on Open Source Community's side).
Branding is more important than ever: If all LLMs perform within 3% and it's more or less indistinguishable, then public perception and enterprise partnerships obviously get more important. Perhaps the LLM provider doesn't have much of a negotiating power. This also might mean that it's okay to be a fast follower in the LLM space. Can Oracle or Amazon "give away" a slightly shittier, neutered LLM that basically piggybacks on GPT to get more cloud contracts? Probably.
Scientific Implications
The Alpaca model announcement also has important scientific implications.
- Perhaps we could just automate the whole LLM fine-tuning process: Stanford showed that it only takes 2 days and $600 to piggyback another model. Why not just run N=100 number of these jobs, ensemble them, and retrain models at some cadence? This shows one way that small research teams can contribute to LLM research.
- Meta-learning (how to chain together LLM calls to simulate meta-cognition) is where the research is headed. The value-add will be in creating meta-frameworks for leveraging individual LLM calls (Langchain is an attempt at this, but I'm sure better frameworks will come out) to simulate higher-level cognition. Even this could probably be learned by some fine-tuned model, and the output of this would probably be then mimicked by another model, and so on.
This Leads to the “AI is Headwind for Tech Valuations” Thesis
If the market leader LLMs indeed don’t have much competitive advantage as we thought, then what will? It’s one thing to create value with AI, and another to capture it. This is why I laid out why it’s unclear that AI is positive for tech stocks.
Conclusion
In conclusion, the Alpaca model announcement from Stanford University has significant implications for businesses and the scientific community alike. There is less competitive moat for foundational API providers. Furthermore, generative AI models will only get better, faster, and foundational models will become more and more sample efficient. Businesses must take note of these developments and adapt accordingly. In the field of generative AI, it is clear that the future is bright, and we can expect to see even more groundbreaking developments in the years to come.